Apache Hadoop is a suite of open-source components which serve as the building blocks of large distributed systems.
An obvious question to ask is 'why Hadoop?', why not just slap a load-balancer over a few NGINX frontends and a few beefy MySQL servers? The simplest answer is gradual scaling: Hadoop components are designed to scale horizontally as the system need to handle more load; just add more nodes to the systems under contention. This means that if your service takes off and goes from 1M to 100M users in a matter of months, an old-style architecture with MySQL instances would start breaking down at the single points of contention. Then the engineers start manually sharding the database and basically re-building systems that eventually converge to be sloppy imitation of Hadoop components. At this point, you will not be as nimble as a team that picked the right building blocks.
Some of the world's best apps and websites are powered by Hadoop. If you want to understand how to build world-scale web services, understanding the principal Hadoop components is a good place to start.
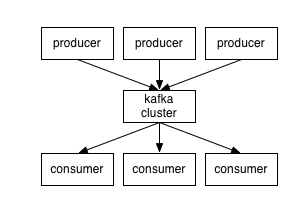
Kafka is a publish-subscribe distributed messaging system implemented on a log abstraction. Publishers write to topics, any number of clients can subscribe to that topic and get notified when a new event happen.
The base abstraction in Kafka is a distributed log. This log allows to define an authoritative order for the events in the system as well as allowing buffering between producer consumer (a producer can produce N messages, the consumer does not have to immediately consume them). However, that log has a maximum size and retention period, so if the events are not consumed within a period of time, they vanish.
Kafka is organized by topics, which are a name that producer and consumer agree to use for a specific event stream. For example, you could think of a topic being "Picture7564_Comments". The producers write to that topic when a user comments on the picture, and clients subscribed to that topic get a notification whenever a new comment is added on that picture.
The topics are broken-down by partition. Partitions are used to provide scaling, parallelism and ordering guarantees. Messages in the same partition are totally ordered on the server, and deliver in-order to the client. However, between partitions, message on a topic have no ordering defined. A partition is attributed to a server, so having only one partition per topic limits the throughput.
Kafka replicates the data on multiple servers. Replication factor is a configurable setting, setting it to one will yield the best performance but risk permanent message loss on a hard-disk failure. When the replication factor is N, it guarantees that unless N-1 nodes fail at the same time, the message will not be lost and be readable by the consumer.
Kafka is designed to be a real-time system; the delay between an event being published and consumed is expected to be less than 100ms.
Paper: Kafka: a Distributed Messaging System for Log Processing
Similar system: Rabbit MQ
Links:
http://kafka.apache.org/documentation.html
http://blog.cloudera.com/blog/2014/09/apache-kafka-for-beginners
Use cases:
ZooKeeper is a distributed coordination service which is used when nodes in a distributed system need a single source of truth. Most of Hadoop's other components (e.g. Kafka, HDFS, ...) use ZooKeeper internally.
It is implemented as a single (movable) master with N coordinated nodes. A majority of nodes (n/2+1) must agree on a change before the change is accepted. The write requests have to be processed by the master (so the write rate is severely limited), but the read requests can be answered by any of the coordinated nodes.
The basic unit of interaction are znodes which are file-like entities addressable under a path:
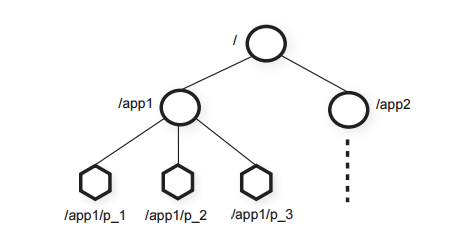
ZooKeeper provides a low-level API that allows to do just a few fundamental operations on those znodes. For example (but not limited to):
getData(path, watch)
setData(path, data, version)
Guarantees: The clients are not guaranteed to all have the same view at the same time (because of network delays and network segmentation, some clients might have information from a previous state). But the clients are guaranteed to all view the changes in the same order.
Example Use-Cases: distributed lock, group membership and configuration management.
ZooKeeper provides very low-level abstraction, and implementing scenarios like leader election can be really hard to do well. Usually people will use the Curator library which implements higher-level concept on top of the ZooKeeper API.
Similar system: Google's Chubby.
Paper: ZooKeeper: Wait-free coordination for Internet-scale systems
Links:
Uses Zab (a Paxos alternative): paper::"Zab: High-performance > broadcast for primary-backup systems" as consistency algorithm.
https://www.elastic.co/blog/found-zookeeper-king-of-coordination
Distributed data-store which is highly available and guarantees no data-loss even in case of multiple server and hard-disk failures. Think of HDFS as a distributed file store that guarantees high-throughput for read and writes and well as durability. HDFS gives a file-like interface: you can read, write and delete files which are organized under a hierarchical folder structure.
Internally HDFS uses a master / coordinated nodes design. The master node is called the `NameNode` and the coordinates nodes are called `DataNode`. Files stored in HDFS are broken down in blocks (typically ~128MB), and the blocks bytes are stored in the DataNodes. The NameNode is responsible for managing the filesystem namespace and regulating access to files by clients. It stores the block to DataNode relation. DataNode are responsible for storing the data and directly handling read / write streams. So when a client wants to read a file, his request has to first go to the MasterNode to know which DataNode hold the blocks for this file. Then the client connects directly to the DataNodes and reads the data.
It may seem odd that all read / writes need to go through the unique NameNode, this introduces an obvious performance bottleneck. However, the operations that the NameNode has to do (looking up file -> block information from RAM and filesystem metadata changes) are light, and the costly operations (actually reading / writing the data) are done by the DataNodes, so the bottleneck is not that severe. The NameNode uses a synchronously-replicated transaction log for metadata changes so that HDFS can recover from a NameNode permanent failure.
HDFS maintains N (usually 3) copy of all blocks at all times. It verifies that N copies are always healthy, and if some of the copies have vanished (e.g. hard-disk failure) it will create new copies of the data until the replication factor goes back to N.
Paper: The Hadoop Distributed File System
Similar systems: GFS, Amazon S3, Azure Blob storage
Cassandra is a distributed database which scales linearly as nodes are added to the cluster. Cassandra has more structure than a simple key-value store but less structure and guarantees than a full-on relational database. It provides an SQL-like language (called CQL) for data-operations. Cassandra is optimized for fast writes (reads are more expensive) and is eventually consistent. There is support for atomic operations for data in the same node. In contrast to most storage systems, all nodes are homogeneous -- there is only one type of node in Cassandra and no underlying dependency on HDFS or ZooKeeper.
Data in Cassandra is organized in tables, which are themselves broken down in rows and columns. A (table, key, columnName) represents the address of data. Unlike a relational database, Cassandra does not force all keys in a table to have the same set of columns. Tables in Cassandra are sharded by primary key (which identifies a row of data) and clustered by clustering key. The shard defines which machine owns the row. Clustering defines the order the data is written in. Rows can have time limited data (set TTL on write) and specify triggers (action that happen when data changes).
Cassandra is designed for high write throughput, at the cost of read speed. This is due to using a log-structured merge-tree (LSM-Tree) as opposed to B+ tree which is ubiquitous in most other databases (e.g. MySQL). Briefly, a LSMT database strive to write data sequentially since sequential write is much faster than random write for both HDD and SSD. Data is kept in a cache and a set of files which contains sorted data. When the number of files gets too large, compaction merges N-files together. The cache can return read operations for most recently used data, but reading colder data is costly since it must be binary-searched in the sorted files. Writing is very fast because it is mostly just appending data to a file.
Cassandra allows fine-tuning of data replication settings on a per-table basis. The default mode is quorum, where a R + W > N consensus is necessary in order to accept a write or server a read. Lightweight transactions are also possible through the IF clause, but (of course, there is no free lunch) at the cost of giving-up availability.
Unlike Amazon Dynamo, Cassandra does not use vector clocks. Rather, it relies on a last-write-wins scheme and hopes that clock skew is minimal. This is a weak point of Cassandra, in the case of network partition, two clients can end-up writing a key on different nodes. If the nodes do not have a synchronized clock, last-write wins means that one of the two clients (not necessarily the one that wrote data last) will have his data overwritten and not be aware of it.
Paper: Cassandra - A Decentralized Structured Storage System.
Similar system: Amazon Dynamo, Google BigTable, Azure Table, HBase, Riak.
A few distinctions between the systems:
Links:
Spark is a framework to run large-scale, data-intensive workloads on commodity hardware. It is especially useful for workflows that are currently difficult to implement or expensive to run on Hadoop MapReduce.
MapReduce is not well suited for iterative jobs and interactive analytics because it forces the materialization of results between jobs (generally to HDFS). In iterative jobs, keeping the data between iteration in RAM results in a significant speedup. For interactive jobs, consecutive ad-hoc queries can often be answered by the same working-set of data that could be kept in memory between queries (MapReduce forces every query to read/write data to HDFS).
The main concepts that Spark introduces are resilient distributed datasets (RDDs) and lineage. RDDs are collections of objects partitioned over a set of machines. They limit data transformation (to: map, filter, sample, reduce, ...) and track how the partition set relate to each other through their lineage. If a partition is lost, the lineage allows to efficiently re-compute the data of that partition.
So, using Spark allows to distribute computation over an arbitrary set of nodes in an efficient way which deals with the reality of a distributed system where some of those nodes will occasionally fail and necessitate data recovery and re-computation.
The initial Spark paper is a good overview.
Links:
